~ / Markdown Link Fixes & Code Formatting
August 12, 2024
In my post about this blog I mentioned markdown links, well I actually have encountered my first set of problems. I want to be able to share code here for future reference. And linking is still missing some features.
Here is my python code for processing links before any fixes:
def process_links(content):
# Handle image links and convert them to <img> tags
content = re.sub(
r'!\[([^\]]*)\]\((http[s]?://[^\)]+)\)',
r'<img src="\2" alt="\1">',
content
)
# Handle plain text image links without a protocol and check /static/images/
content = re.sub(
r'!\[([^\]]*)\]\(([^)]+)\)',
lambda m: f'<img src="/static/images/{m.group(2)}" alt="{m.group(1)}">' if not re.match(r'http[s]?://', m.group(2)) else m.group(0),
content
)
# Handle links with protocols and ensure they open in a new tab
content = re.sub(
r'\[([^\]]+)\]\((http[s]?://[^\)]+)\)',
r'<a href="\2" target="_blank">\1</a>',
content
)
# Handle links without protocols and convert them to absolute URLs
content = re.sub(
r'\[([^\]]+)\]\(([^)]+)\)',
lambda m: f'<a href="http://{m.group(2)}" target="_blank">{m.group(1)}</a>' if not re.match(r'http[s]?://', m.group(2)) else m.group(0),
content
)
# Handle links without protocols and convert them to /post/link format
content = re.sub(
r'\[([^\]]+)\]\(([^)]+)\)',
lambda m: f'<a href="/post/{m.group(2)}">{m.group(1)}</a>' if not re.match(r'http[s]?://', m.group(2)) else m.group(0),
content
)
# Handle plain text links (e.g., [link] with no URL specified)
content = re.sub(
r'\[([^\]]+)\]',
r'<a href="/post/\1">\1</a>',
content
)
return content
I want to add one more link handling feature.
I have escaped the following lines to better demonstrate.
When its just [gr] it works fine linking to /post/gr/
but i also want the following to work:
[ricoh gr](gr)
When an extra () bracket is added and no url is specified convert this to link the specified blog post as /post/(\<link>)
Markdown Code For Links (Rendered as Code Snippet):
[gr]
[ricoh gr](gr)
[ricoh gr](https://www.ricoh-imaging.co.jp/english/products/gr-3/index.html)
Rendered:
Python Code to Fix:
# Pattern to handle [text](relative_path) format
content = re.sub(
r'\[([^\]]+)\]\(([^)]+)\)',
lambda m: f'<a href="/post/{m.group(2)}">{m.group(1)}</a>' if not re.match(r'http[s]?://', m.group(2)) else m.group(0),
content
)
Code Formatting
The way code blocks are specified is using three of the following symbols ` as block indicators.
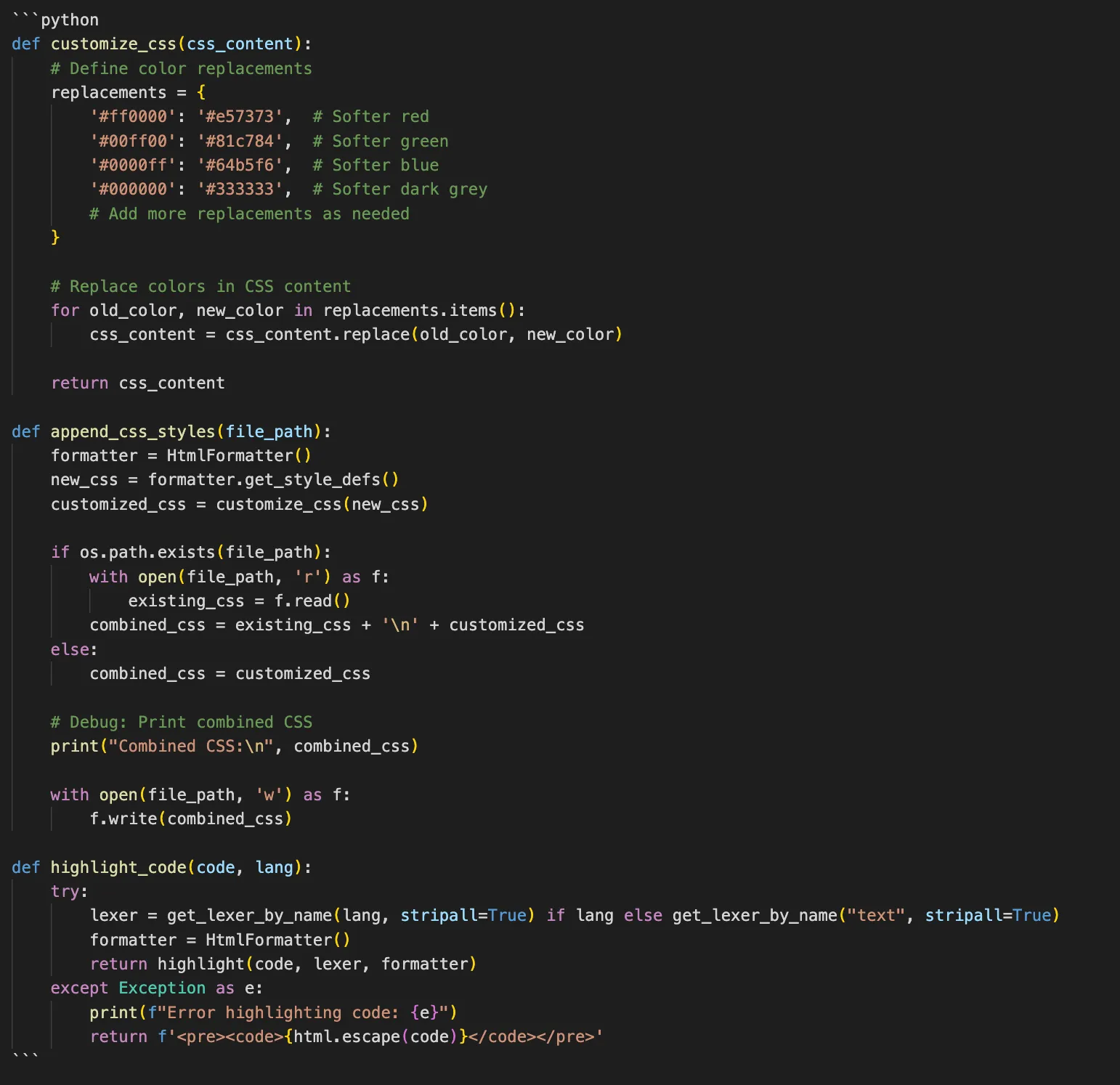
The current code to handle code highlighting.
def customize_css(css_content):
# Define color replacements
replacements = {
'#ff0000': '#e57373', # Softer red
'#00ff00': '#81c784', # Softer green
'#0000ff': '#64b5f6', # Softer blue
'#000000': '#333333', # Softer dark grey
# Add more replacements as needed
}
# Replace colors in CSS content
for old_color, new_color in replacements.items():
css_content = css_content.replace(old_color, new_color)
return css_content
def append_css_styles(file_path):
formatter = HtmlFormatter()
new_css = formatter.get_style_defs()
customized_css = customize_css(new_css)
if os.path.exists(file_path):
with open(file_path, 'r') as f:
existing_css = f.read()
combined_css = existing_css + '\n' + customized_css
else:
combined_css = customized_css
# Debug: Print combined CSS
print("Combined CSS:\n", combined_css)
with open(file_path, 'w') as f:
f.write(combined_css)
def highlight_code(code, lang):
try:
lexer = get_lexer_by_name(lang, stripall=True) if lang else get_lexer_by_name("text", stripall=True)
formatter = HtmlFormatter()
return highlight(code, lexer, formatter)
except Exception as e:
print(f"Error highlighting code: {e}")
return f'<pre><code>{html.escape(code)}</code></pre>'